Concepts
About multi-backend routing
Why the proxy is a control plane over your storage, not another place your bytes live.
A common first question is "does this replace S3 or proxy to it?" Proxy. DeltaGlider never terminates your data — it holds the routing table, the IAM database, and per-object metadata, while the actual bytes live on whatever backends you point it at: AWS S3, any S3-compatible provider, or a local filesystem path. That split — control plane in the proxy, data plane in the backends — is the design decision everything else on this page follows from.
The data path#
Your client speaks the standard S3 API to the proxy; the proxy authenticates the request, decides whether the object is delta-eligible, runs xdelta3 if so, and reads or writes the actual bytes on whichever backend that bucket is routed to.
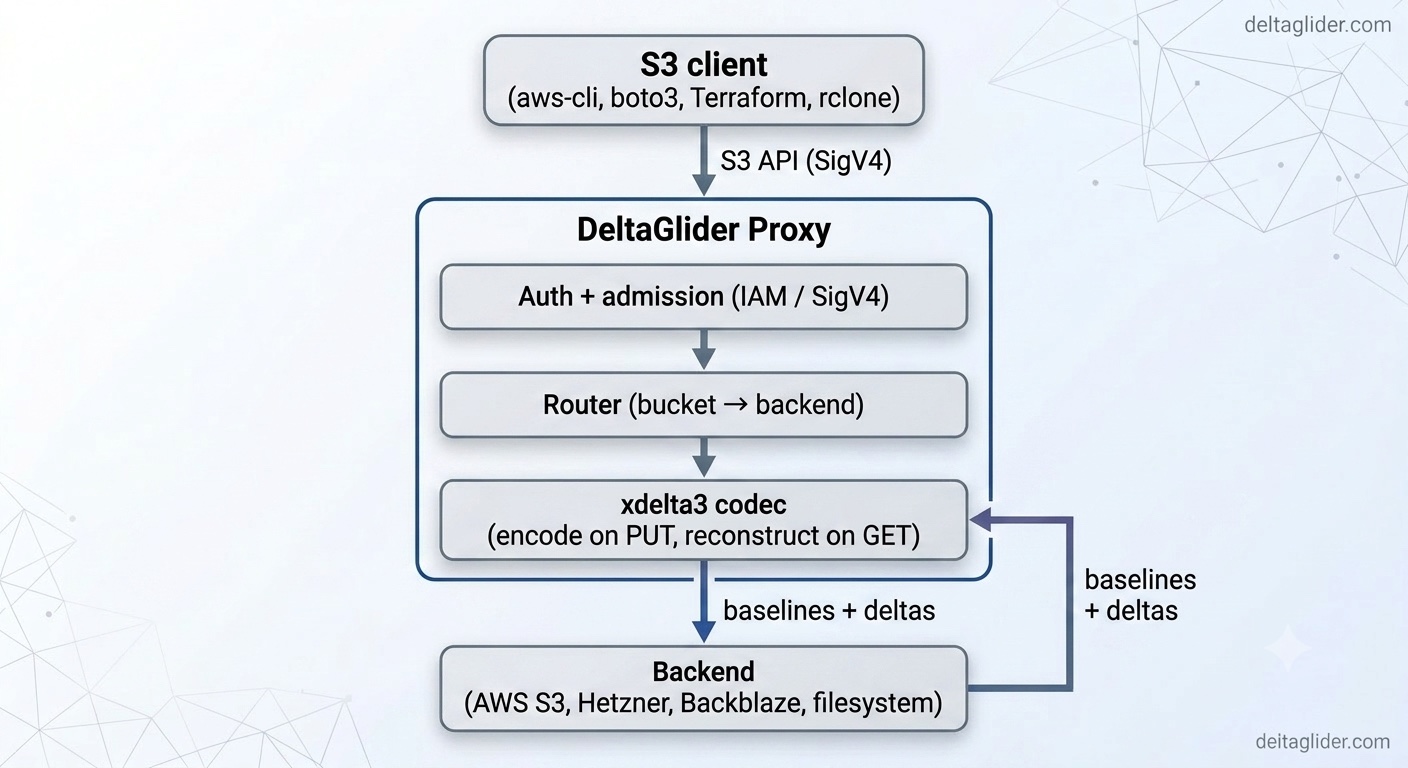
The control plane (IAM, routing table, per-object metadata, jobs) lives in the proxy; the data plane (your bytes) lives on the backends. Everything below follows from that split. For the encode/reconstruct mechanics see how delta compression works; for the CPU/RAM cost of a proxy that actively rewrites payloads, see capacity planning.
One endpoint over many backends#
Consider how Acme runs it. Their admin, dana, registers three backends: hetzner-fsn1 (cheap S3-compatible storage in Falkenstein), local-disk (a filesystem path on the proxy host), and aws-dr (an AWS bucket kept as a disaster-recovery target). She then routes buckets across them: releases — the firmware artifacts that ci-uploader pushes — lives on hetzner-fsn1; db-archive, where backup-bot drops nightly Postgres dumps, sits on local-disk; and DR copies replicate to aws-dr.
Here's the point: neither ci-uploader nor backup-bot knows any of this. Both talk to the same endpoint, same port, same SigV4 credentials. The Engineering group's permissions are expressed against bucket names, not backends. You run the binary, point your S3 clients at it, and the question of where bytes physically land becomes an operator decision made in one place — not a constant scattered across every client config. The proxy serves the S3 API and the admin UI on a single port, sits happily behind an ALB or any reverse proxy, and treats a directory on disk as a first-class backend, which makes "start on local disk, graduate to S3" a routing change rather than a migration project for your clients.
Aliasing as decoupling#
A virtual bucket name doesn't have to match the upstream bucket name. releases might map to a bucket called acme-prod-releases-fsn1 on Hetzner — provider-mandated naming, region suffixes, and legacy conventions stay on the backend side of the line.
This buys more than tidiness. The virtual name is a stable contract with your clients; the mapping behind it is yours to change. When Acme decides Hetzner pricing no longer justifies the latency, dana runs the built-in migrate job: the proxy copies releases to the new backend, verifies, and flips the route. CI pipelines, download scripts, Terraform state — none of them notice, because none of them ever knew where the bytes were. Without aliasing, a provider move means hunting down every client that embeds the old endpoint. With it, the move is a Tuesday.
Why replication lives in the proxy#
The obvious cheap alternative — aws s3 sync or rclone in a cron job, copying from one backend to another behind the proxy's back — is worse than it looks, for three reasons.
First, it bypasses the engine. Objects on the backend are deltas and ciphertext; a dumb byte copier would replicate fw-1.4.1.tar.delta to a destination that has a different reference baseline (or none), producing objects that can never be reconstructed. Second, DeltaGlider's metadata doesn't survive the trip through tools that don't know about it. Third, storage-native replication (S3 CRR, rsync) can't cross encryption boundaries — if hetzner-fsn1 and aws-dr use different proxy-side keys, no backend-level copy can ever be valid on the other side. The remaining option, having every client dual-write, pushes the problem onto the people least equipped to own it.
So replication runs at the engine seam: the proxy GETs the object from the source as plaintext — reconstructed, decrypted, verified — and PUTs it to the destination through the same pipeline as any client write. Each side independently decides whether to delta-compress and which encryption to apply. aws-dr can hold the same logical objects under a different key, with deltas computed against its own baselines. And because replication is a durable job rather than a shell script, it survives restarts mid-run, keeps run and failure history, and can be paused — the difference between a copy you hope happened and one you can audit.
HA and the config-sync trade-off#
The proxy process is stateless about object data, so horizontal scaling is mostly trivial: run several instances against the same backends. Two pieces of state are genuinely shared, both through a designated S3 sync bucket. The encrypted IAM database is deliberately simple — after every mutation, the instance uploads the encrypted DB; other instances poll every five minutes and download when the ETag changes. Replication leadership is the second: each rule's leader holds an S3 conditional-write lease in the same bucket, so a dead leader fails over to a peer automatically instead of two instances double-running the rule. Because the leases depend on atomic conditional writes, the proxy probes the bucket's backend at boot and refuses to start on one that silently ignores them.
That's last-write-wins with a polling lag, and we'll defend it honestly. IAM mutations are rare, operator-driven events; building consensus machinery for them would be engineering against a problem this deployment shape doesn't have. But know the edges: two admins mutating different instances inside the same window means one write wins and the other silently loses, and a freshly created credential takes up to five minutes to work on other instances unless you force a pull. And sync is replication, not backup — a bad mutation propagates to every reader, which is why you take point-in-time Full Backups as well.
Trusting cheap storage#
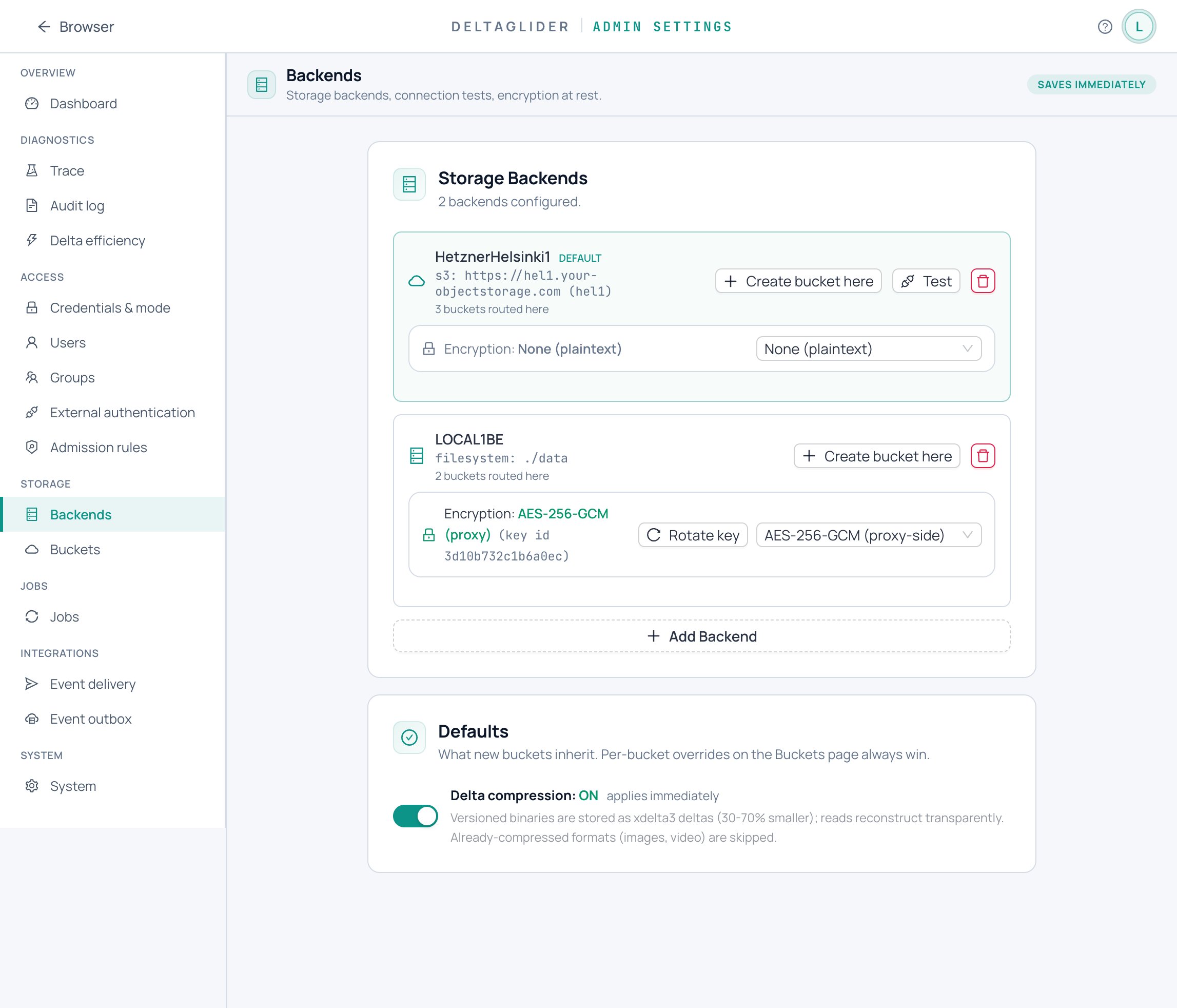
The deepest consequence of the control-plane split: the backend only ever needs to be a dumb, durable byte bucket, because everything requiring trust happens proxy-side. With proxy-side AES-256-GCM on hetzner-fsn1, the provider stores ciphertext and the key never leaves your runtime; compression runs before encryption, so the savings survive. SHA-256 verification on reconstructed reads means backend bit-rot surfaces as an error, never as corrupt data. The honest caveat: object names, sizes, and user metadata stay visible to the backend — keep secrets in object bodies, not key names. Within that boundary, the cheapest S3-compatible storage you can find is exactly as trustworthy as the proxy in front of it. One capability caveat, though: some cheap backends (Backblaze B2, notably) don't enforce conditional writes, which multi-instance deployments need for safe concurrent client writes. The proxy validates this at startup and refuses unsafe combinations; mark such a bucket replication_target_only to use it as a mirror anyway — see How to use non-CAS backends safely.
Related#
- How-to: Route a bucket to a backend
- How-to: Run multiple instances
- Reference: Configuration