Concepts
About jobs, write gates, and durability
DeltaGlider Proxy runs four kinds of background work — replication rules, lifecycle rules, bucket re-encryption, and bucket migration — and presents all of them on one surface. This page explains why that's one surface and not four, why some jobs deliberately block writes, and what "durable" actually means here.
One surface for four kinds#
The operator's mental model should be: anything that runs in the background is a job, and every job has runs, failures, and actions. Whether Acme is mirroring releases to aws-dr, expiring db-archive dumps after 90 days, or re-encrypting a bucket after a key change, the questions are identical — is it running, when did it last run, what failed, can I pause it? Four bespoke screens would mean four places to look during an incident, and four slightly different vocabularies for "it's stuck." So there's one jobs list, one runs/failures drawer, and a per-kind capability matrix (you can pause a rule but not a migration; you can cancel a migration but not a rule) rather than four APIs.
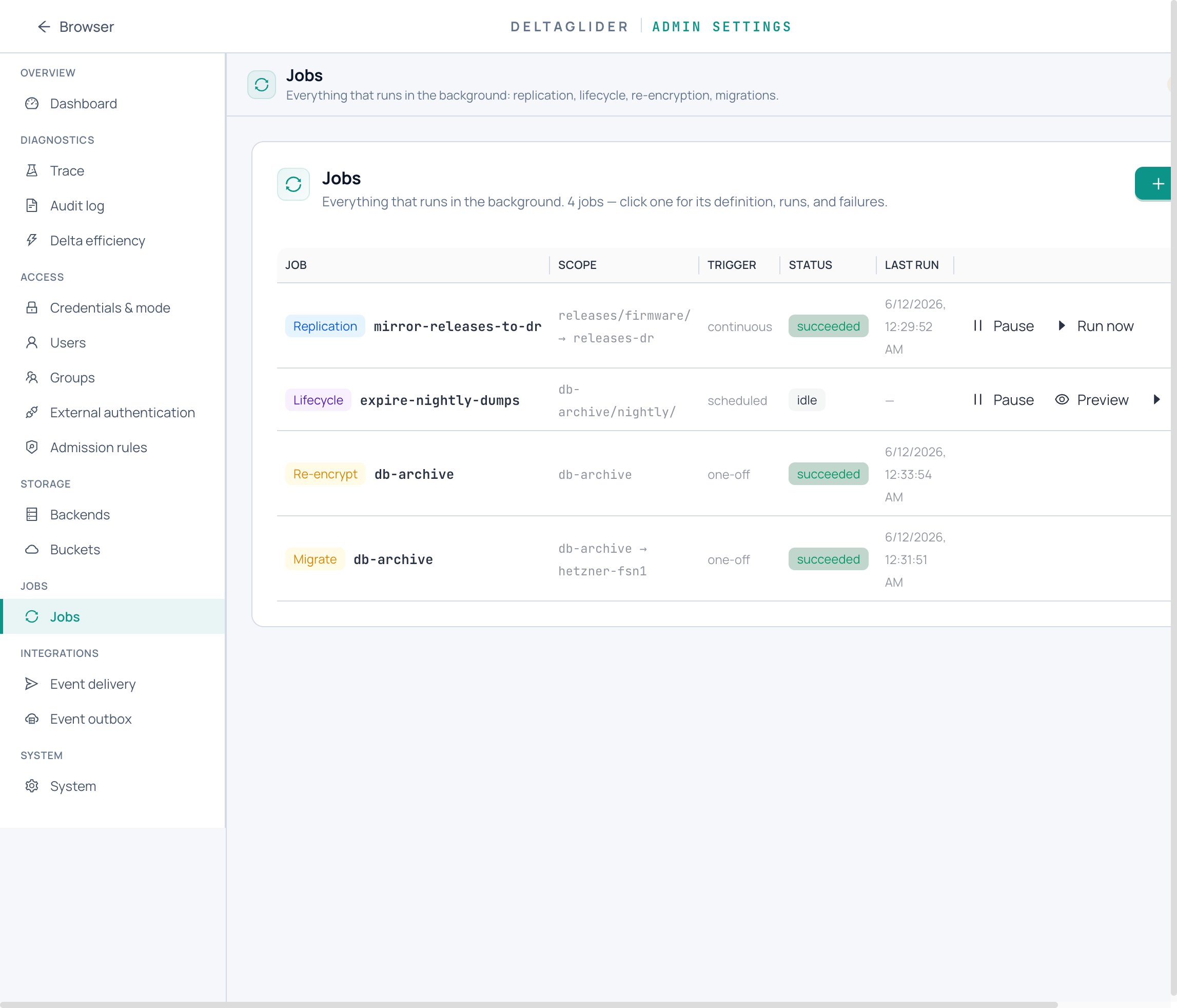
Rules vs one-offs#
Two shapes exist because the work is genuinely two-shaped. Rules — replication and lifecycle — are recurring policy: they belong in YAML, reviewed in git, identical across replicas, with runtime state (cursors, pause flags, run history) kept separately in the config DB so a config reload doesn't forget what's been done. One-offs — re-encrypt and migrate — are born from an operator action, not a policy file; they're created via API or GUI, live entirely in the DB, and are their own single run. Forcing a migration into YAML would mean committing a file to express "do this once, now"; forcing replication into the DB would hide standing policy from code review. Each shape lives where its authorship lives.
Why maintenance jobs take a write gate#
While a re-encrypt or migrate job works a bucket, S3 writes to that bucket get 503 SlowDown; reads pass untouched. This is consistency chosen over availability, deliberately.
Consider the race the gate prevents: a re-encrypt job is sweeping db-archive after a key rotation while backup-bot PUTs tonight's dump. Without the gate, that PUT can land under the old configuration after the sweep has passed its key — and the job finishes "successfully" with one object silently stranded under a key you're about to retire. A migration has the same race with a worse ending: a write to the old backend after the copy phase simply vanishes when traffic flips.
503 SlowDown is the honest trade because it's a protocol-native refusal: AWS SDKs back off and retry automatically, so backup-bot doesn't fail — it waits. The gate engages at job creation (no window between deciding and claiming), drains in-flight writes before copying, and lifts the moment a migration flips routing — before optional source cleanup, so the unavailability window is the copy, not the cleanup.
This is also the place to mention soft quotas, which sit at the opposite end of the same trade. Bucket quotas read from a usage scanner whose results are cached for five minutes, so a burst of concurrent writes can overshoot the limit by a few minutes of throughput. Quotas are soft because making them hard would put a synchronous full-bucket size check on every PUT — paying a heavy tax on the hot path to enforce a budget number. Where the write gate buys strict consistency with temporary unavailability, soft quotas buy hot-path speed with approximate enforcement. If you need a hard cap, enforce it at the storage provider.
What "durable" means here#
Every job survives a proxy restart, and that's a specific set of mechanics, not a slogan. Long-running work persists a continuation cursor, so a run interrupted mid-page resumes where it stopped instead of rescanning from the top (with a one-shot guard that restarts fresh exactly once if the stored cursor turns out to be poison). Leases stop two instances — or the scheduler and a run-now click — from executing the same rule concurrently, and a lapsed lease never resurrects; replication's lease lives as an S3 conditional-write object when a coordination bucket is configured (cross-instance failover), lifecycle and maintenance leases live in the config DB. On boot, runs left in running by a dead process are marked failed with an operator-visible row, and pending maintenance jobs are re-queued — a restart mid-migration resumes the migration rather than orphaning a half-moved bucket. A cancelled migration before the routing flip unwinds cleanly; the source is never deleted on a failed run.
The event outbox: the durable journal underneath#
Two features — webhook/Slack notifications and event-driven replication — share one foundation: every successful object mutation appends a fact to a durable event_outbox table, and consumers drain it on their own cursors. The append is the only thing the S3 write path does; delivery never blocks a PUT, a dead webhook endpoint can't slow uploads, and a missed event survives a crash because it's a row, not an in-memory message. This is why replication can be "near-real-time" without being fragile: the outbox is the primary trigger, and a slow periodic reconcile sweeps up anything a consumer missed.
Lifecycle vs replication#
They share the transfer machinery but honor different contracts. Replication continuously mirrors a live source: event-driven, with conflict policies and optional delete propagation — its promise is "the destination converges on the source." Lifecycle is age-driven housekeeping: it acts only on expired candidates, deleting or transitioning them, optionally removing the source after a verified copy — its promise is "old data goes away, or goes somewhere colder." Because both copy through the engine, multipart ETags, encryption routing, and compression behave identically; the difference is purely when they act and what they promise about the destination.
Related#
- How-to: Move a bucket between backends
- How-to: Replicate a bucket
- Reference: Jobs
- Reference: Event log